|
情報圧縮 Source coding |
|
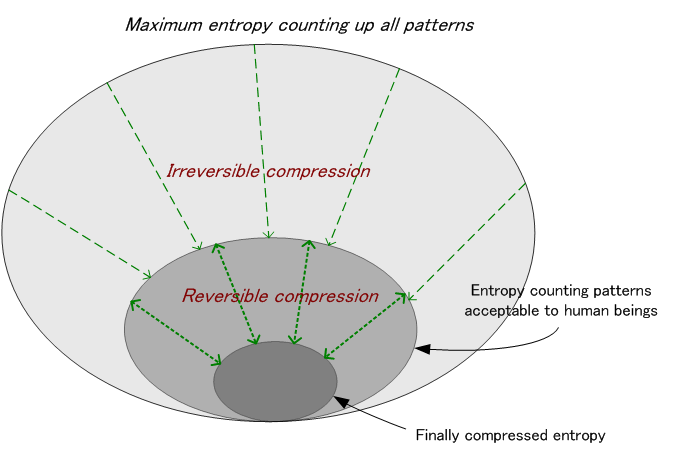
情報圧縮は可逆(圧縮して伸長すると正確に元に戻る)と非可逆(圧縮して伸長したら正確に元に戻らない)に分けられますが、情報理論として体系的に扱う範囲は可逆のみです。 実際の情報圧縮では、まず非可逆によって圧縮し、その後で可逆圧縮をかけます。 非可逆圧縮技術に立ち入るには、対象とする情報源固有の性質を勉強する必要があります。 すなわち、音声や楽音や画像といった情報の性質やそれを受ける人間の受容器官の特性などをフルに利用して、ユーザーが許容可能な限界まで圧縮します。 この限界を極めるために、大量の主観評価が行われます。 このような非可逆圧縮の後、残った強いマルコフ性(人間が理解できる規則性)をその頻度分布の偏りを利用して可逆圧縮します。 下図はその概念です。
ときどき、「圧縮して伸長しても原画とほとんど見分けがつかないから可逆(loss-less)だ」 などといいますが、これは上図の可逆変換(灰色部分)を指します。 可逆は正確に元の情報に戻ることを意味します。 注: 非可逆圧縮を経由しないで、最初から可逆圧縮のみで圧縮することは、装置規模は莫大になるかもしれないが、実施することは可能。 理論的な限界まで可逆だけで圧縮した結果が、上図のように非可逆圧縮して可逆圧縮した結果とどんな関係にあるかは、一般論として議論できそうもない。 人間の特徴抽出能力が理論的な可逆圧縮で記述できるかどうか・・・? 可逆圧縮の概要は以下のようです。 前後の脈略なく、アルファベットをランダムに出力しているような情報源を無記憶情報源といいます。 現実の情報源では、アルファベットの出現確率は「前後の脈略」に支配されます。 たとえば、英語では
q の後にはほとんどの場合 u が続きます。 このようにアルファベットの発生がそれ以前のアルファベットに依存する情報源をマルコフ情報源と呼んでいます。 情報圧縮の理論は、まず無記憶情報源について理論体系を作り、この理論体系を拡大されたマルコフ情報源に適用します。 マルコフ情報源は拡大することによって近似的に無記憶情報源とみなすことができるからです。 のように符号化 (Coding )すると、1アルファベット当り2ビットを用いることになり、この値は4文字を出力する情報源の中で最大のエントロピーをもつものになります。 次に、4つのアルファベットの出現確率に偏りがある情報源を考えてみましょう。 たとえば、
としてみます。 この情報源のエントロピーは
になります。 すなわち、この情報源は、1アルファベット当り、平均
を「冗長度」と呼んでいます。 では、冗長部分を削って符号化するにはどうしたらよいでしょうか? 直感的にいえば、出現頻度の小さいアルファベットには長い符号を、大きいアルファベットには短い符号を割り付けると、平均として短い符号化ができます。 このような符号を不等長符号と呼びます。 上の情報源に対して、
のように符号化すれば、平均ビット長は
となり、たまたま、情報源のエントロピーに等しくなりました。 もちろん、符号化は復号(元のアルファベットに一意に戻すことが)できなくてはなりません。 code1 も code2 も、アルファベットと符号の対応表をもっていれば、一意に復号できることがいえます。 いくら能率の良い不等長符号でも、幾通りもの文章に復号できたのでは、符号化の役を果たしません。 情報圧縮(可逆)の目的は、復号可能な符号化の中から、 符号化とエントロピーの間には密接な関係がありますが、上の不等長符号の説明に関して、二つの疑問が湧きます。 疑問(1) code2 の平均符号長はちょうど情報源のエントロピーに等しかった。 上の答えはノーですが、もしそうならば、最も平均符号長の短い符号をみつけたくなります。 code2 はたまたま情報源のエントロピーにピッタリ一致しましたが、こんなことは稀であり、一般にはエントロピーが下限です。 疑問(2) では、もっとも短い符号をどうして見つければいいでしょうか? 答えはイエスです。 これらの疑問は情報源符号化の基本概念に関わってきます。 詳しくは、復号可能、ハフマン符号、符号とエントロピーを参照してください。 |