|
平均情報量 Entropy |
|
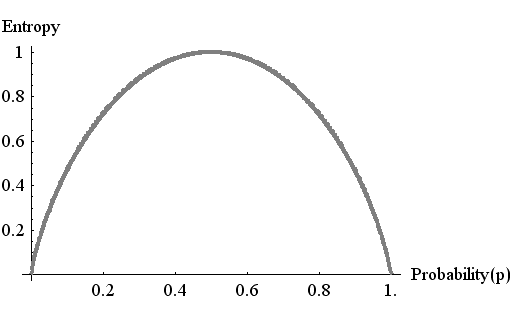
平均情報量(エントロピー)は、その情報源がどれだけ情報を出しているかを測る尺度です。 物理学でも、頻繁にエントロピーという言葉が出現しますが、その意味は 「乱雑さ」 「不規則さ」 「曖昧さ」 などといった概念を指します。 情報理論の場合もまったく同じ概念を指し、その情報が不規則であればあるほど、平均として多くの情報を運んでいることを意味します。 二つのアルファベット A 、 B がランダムに出力されているとします。 こように、アルファベットが過去に依存しないで、独立に出力される情報源を無記憶情報源と呼んでいます。 それぞれの確率を
の情報を得ることになります。 これが2種類のアルファベットの場合の平均情報量(エントロピー)です。
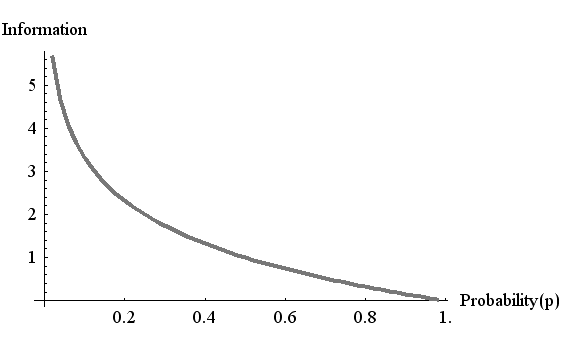
この図は、アルファベットの出現頻度に偏りがあるとエントロピーが小さくなることを表しています。 たとえば、「ハイ」ばっかり言う人は、平均として情報をあまり表現していないことを主張しています。 でも、このような人に、たまに「イイエ」と言われると、われわれはかなり驚きますね。 このとき、われわれは、下図の情報量のカーブからも分かるように、ものすごく大きい情報を知らされるわけです。 でも、普段は「ハイ」ばかりですから平均すると、この人が発する情報量は平均として小さいと言えるのです。 これは、情報量が対数関数で定義されたことに由来しており、統計的に情報を扱う範囲では、妥当なことなのです。 念のため、3つのアルファべット A 、B 、C をランダムに出力する場合はどうでしょうか? それぞれの発生確率を
で与えられます。 ここで、アルファベットの発生確率の総和は1なので、
この関係から
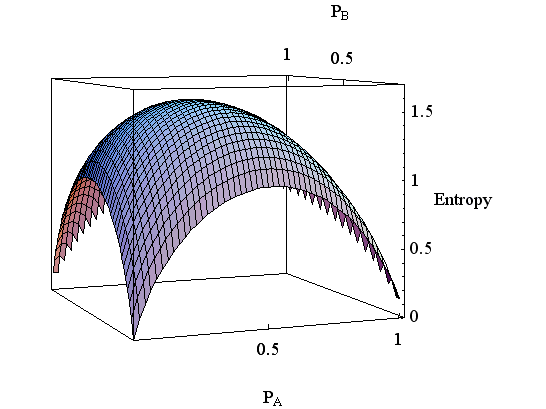
下の図は、2つの水平軸を
アルファベットが3以上の場合も同様に、次の定理が成り立ちます。 定理 無記憶情報源から出力されたアルファべットを一定の長さ n ごとに切り、それを単語とみなします。 すると、この情報源は単語を単位として出力しているとみなせます。 このような情報源の解釈を n次拡大といいます。 たとえば、A 、B 、C の3種類のアルファベットを出力する情報源の3次拡大は、27種類の単語 AAA AAB AAC ABA ABB ABC ACA ACB ACC ・・・・・・・ を出力する情報源です。 これらの単語の出現確率は各文字の発生確率の積ですから、たとえば単語 AAC の出現確率は
で計算されます。 すべての単語についてこの計算を行い、エントロピー
を求めることができます。 すると、
が成り立ちます。 一般に次の定理が成り立ちます。 定理 実は、この定理はマルコフ情報源についても、n が十分大きいとき成り立ちます。 このことが、無記憶情報源について体系化した情報圧縮などの原理がそのままマルコフ情報源に適用できる根拠になっており、実用上極めて重要な定理です。 シャノンは、英文のエントロピーを、 |